
What You Need To Know About Meta S Llama 2 Model Deepgram
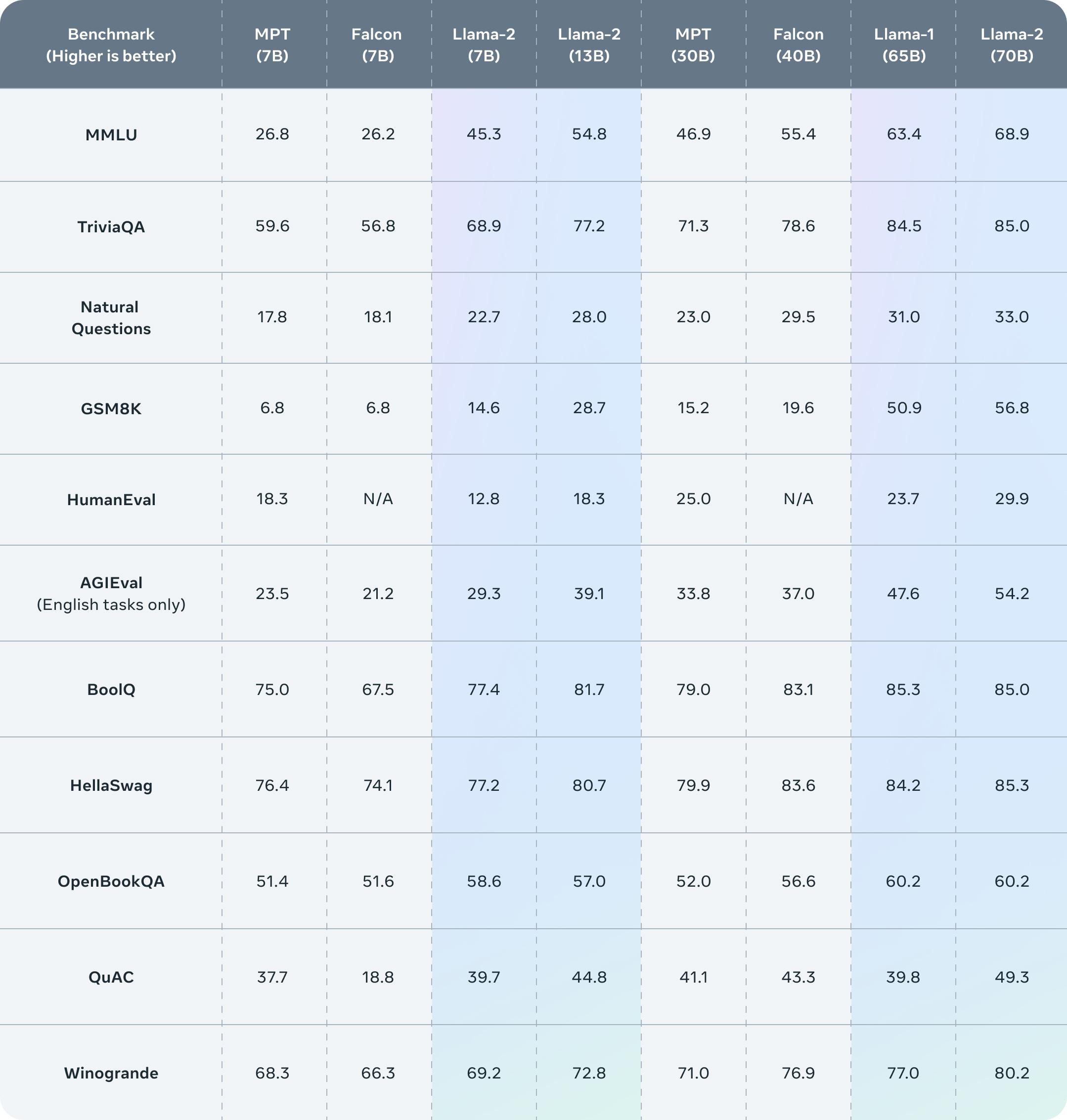
All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models. Check the CPU section for more info on this topic Lest look at some of the hardware requirements you need to cover in order to use LLaMA model on. Sign Up Llama 2 The next generation of our open source large language model available for free for research and commercial use. ..
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM. If it didnt provide any speed increase I would still be ok with this I have a 24gb 3090 and 24vram32ram 56 Also wanted to know the Minimum CPU. Using llamacpp llama-2-70b-chat converted to fp16 no quantisation works with 4 A100 40GBs all layers offloaded fails with three or. Below are the Llama-2 hardware requirements for 4-bit quantization. Most curious about 70B requirement specs According to the following article the 70B requires 35GB VRAM..

Choosing The Right Llama 2 Model
TheBlokeLlama-2-70B-Chat-GPTQ What GPU is needed for this 70B one. This blog post explores the deployment of the LLaMa 2 70B model on a GPU to create a Question-Answering. For 70B models we advise you to select GPU 2xlarge - 2x Nvidia A100 with bitsandbytes quantization. Using Low Rank Adaption LoRA Llama 2 is loaded to the GPU memory as quantized 8-bit weights. ..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in 2023 Released free of charge for research and commercial use Llama 2. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety. We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens and show that it is. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large..



Komentar